Aritalab:Lecture/NetworkBiology/Degree Distribution
次数分布
次数 k が全頂点の中で占める割合 p(k) を次数分布といいます。確率分布なので総和は 1 です。
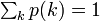
その平均値を、平均次数といい 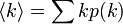 と書きます。
と書きます。
隣接点の次数分布
隣接する頂点の次数を 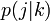 と書きましょう。ここで次数 k の頂点に隣接する頂点の次数が j です。
と書きましょう。ここで次数 k の頂点に隣接する頂点の次数が j です。
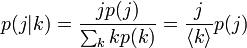
別の言い方をすると、頂点をランダムに選んで次数が j である確率は p( j) ですが、辺をランダムに選んでその先に来る頂点の次数が j である確率が p ( j | k ) です。辺をたどった先の頂点はハブが来やすく、その来やすさは、頂点の次数に正比例します。次数 j の頂点は相対的に j / <k> だけ、現れやすくなっています。
辺の先に来る頂点の次数平均を求めましょう。
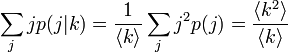
この値は各所で用いますが、k から j をたどる辺 1 本ぶんを最初に引いておく場合もあります。このとき、値は 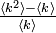 になります。
になります。
全頂点の次数が同じ時 <k2> = <k>2 となるので、隣接点の平均次数は <k> (またはたどってくる辺を除いて <k> - 1) になります。次数の偏りが大きくハブが存在する場合、隣接点の平均次数は <k> を大きくうわまわります、これは隣にハブが来やすいことと同じです。次数がポアソン分布に従う場合、分布の定義から 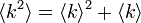 が成り立っています。ポアソン分布の場合、たどる辺を差し引けば、ちょうど隣接点も次数 <k> になります。
が成り立っています。ポアソン分布の場合、たどる辺を差し引けば、ちょうど隣接点も次数 <k> になります。
次数相関
隣接する頂点どうしの次数が似る度合いを次数相関といいます。
- 次数相関
ピアソンの相関係数に従って定義します。M 本ある辺の両端点 u, v の次数をそれぞれ ku, ku とおきます。相関係数の分子は ku, kv の平均からの差分を計算します。 分母は本来 ku と kv の標準偏差の積ですが、ここでは分散を使ってしまいます。
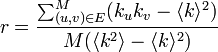
- 辺がランダムに張られるエルデシュモデルでは、次数相関は 0 になります。
- 映画俳優の競演関係ネットワークではハブどうしが隣接しやすい、つまり正の相関を持ちます。 (assortative)
- 生態系ネットワークではハブどうしが独立し、負の相関を持ちます。 (dis-assortative)