|
|
| Line 68: |
Line 68: |
| | 上でみたように、次数の平均値が 1 をこえると急に連結成分のサイズが大きくなり、 log ''n'' に達すると全体が連結になります。 | | 上でみたように、次数の平均値が 1 をこえると急に連結成分のサイズが大きくなり、 log ''n'' に達すると全体が連結になります。 |
| | こうした点を、相転移点と呼びます。 | | こうした点を、相転移点と呼びます。 |
| − |
| |
| − |
| |
| − | ==ネットワークの指標==
| |
| − | ネットワーク全体についての尺度として、クラスター係数 ''C'' と平均頂点間距離 ''L'' を紹介します。
| |
| − |
| |
| − | ===クラスター係数===
| |
| − |
| |
| − | クラスター係数は隣接する頂点間の辺の密度の平均値にあたります。まず各頂点 ''i'' におけるクラスター係数 <math>C_i</math> を以下のように定義します。辺の長さはすべて 1 とし <math>(|e| = 1)</math>、頂点 ''i'' の次数を ''deg'' (''i'' ), 隣接する頂点群を ''adj'' (''i'' ) とします。
| |
| − |
| |
| − | :<math>\textstyle C_i=\frac{2}{deg(i)(deg(i)-1)} \sum_{j,k \in adj(i)} |e_{jk}|</math>
| |
| − |
| |
| − | グラフ全体のクラスター係数はその平均値です。
| |
| − |
| |
| − | :<math>\textstyle C =\frac{1}{n} \sum^{n}_{i=1}C_i</math>
| |
| − |
| |
| − | クラスター係数が 0.2 や 0.3 になるネットワークは、比較的「密」といえます。
| |
| − |
| |
| − | ===平均頂点間距離===
| |
| − | ここでは頂点 ''i, j'' 間の最短経路を <math>p_{ij}</math> と書きます。平均頂点間距離の定義はその字のごとく全頂点間の最短路の平均値です。ネットワーク ''G'' の頂点数を ''n'' とすると頂点の組み合わせの数が ''n'' (''n'' - 1) / 2 あるので
| |
| − |
| |
| − | :<math>\textstyle L=\frac{2}{n(n-1)} \sum_{i,j\in G}|p_{ij}|</math>
| |
| − |
| |
| − | となります。
| |
| − |
| |
| − | 上の定義だと、例えば無限の広がりを持つ場合の平均距離を求められません (無限個の最短路を計算しなくてはならない)。そういう場合は、ネットワーク上のある点に注目して ''L'' を計算する場合があります。その点から距離 ''L'' 以内にある頂点数を数える手法です。
| |
| − |
| |
| − | ==様々なグラフにおける指標の値 ==
| |
| − |
| |
| − | ===完全グラフ===
| |
| − | 全ての頂点間に辺を持つグラフを、完全グラフ (complete graph) といいます。完全グラフでは、 ''C'' = ''L'' = 1 になります。
| |
| − |
| |
| − | ===木、格子===
| |
| − | 簡単のため全頂点が同じ次数を持つ木を考えましょう。中心の頂点 ''v''<sub>0</sub> を根 (root) と呼びます。木はその定義よりサイクルを持たないので ''C'' = 0 です。また平均頂点間距離は、距離 ''L'' 以内にある頂点を数えることで求められます。
| |
| − |
| |
| − | <math>
| |
| − | \begin{align}
| |
| − | n &= 1 + d + d(d-1) + ... + d(d-1)^L \\
| |
| − | &=\textstyle 1 +\frac{d (1-(d-1)^{L+1})}{(1-(d-1))} = 1 + \frac{d}{d-2}((d-1)^{L+1} -1) \\
| |
| − | &\propto (d-1)^{L+1}
| |
| − | \end{align}
| |
| − | </math>
| |
| − |
| |
| − | この関係から(大雑把ですが) <math>\textstyle L=\propto \frac{\log n}{\log (d-1)}</math> となります。
| |
| − |
| |
| − | 格子状のネットワークでは頂点が一定間隔で配置されるため、道路網のような地理的制約をうけるつながりを表現するのに適しています。平面の場合は三角格子、正方格子、六方格子などが考えられます。ただし、クラスター係数を定義のまま適用すると、三角格子以外は隣接頂点どうしがつながらないために常に ''C'' = 0 になります。これでは面白くないので、格子の場合は最短距離が <math>a</math> 以下の点には全て辺を張るバリエーションを考えるのが一般的です。ここでは、''d'' 次元空間において辺の長さが単位距離の格子を '''Z'''<sup>d</sup> と書きましょう。 ( '''Z'''<sup>d</sup> において ''deg''( ''i'' ) = 2 ''d'' )
| |
| − |
| |
| − | ;'''Z'''<sup>1</sup> : いわゆる数直線です。ある頂点から ''k'' の距離内にある頂点は、その数 ''n'' = ''2k'' + 1 です。これらの頂点の平均距離は ''L'' = ''k'' になります。したがって ''L'' ∼ ''n''/2 です。
| |
| − |
| |
| − | ;'''Z'''<sup>2</sup> : 二次元の格子として、正方格子を考えます。ある頂点から ''k'' の距離内にある頂点の数は ''n'' = ''k''<sup>2</sup> + ( ''k'' + 1)<sup>2</sup> です。これらの頂点の平均距離は ''L'' = ''k'' / 2 です。''n'' の式を ''k'' について解くと <math>\textstyle k = \frac{\sqrt{(2n -1)} - 1}{2} \sim \frac{\sqrt{2n}}{2} </math> となるため <math>\textstyle L \sim \frac{\sqrt{2n}}{4}</math> です。
| |
| − |
| |
| − | <!---
| |
| − | :例. '''Z''''<sup>d</sup>のクラスター係数は<math>\textstyle C=\frac{3(a-1)}{2(2a-1)}</math>、平均頂点間距離は<math>\textstyle L=\sqrt[d]{n}/a</math>
| |
| − | --->
| |
| − |
| |
| − | ===Erdős–Rényiグラフ===
| |
| − |
| |
| − | 各頂点が持つ辺の期待値(定数)を c とします。これは c = n p を満たします。
| |
| − |
| |
| − | クラスター係数 ... 辺が張られる確率は全て独立なので p です。n が大きくなると 0 に近づきます。
| |
| − |
| |
| − | 平均頂点間距離 ... 各頂点が持つ辺の期待値を c とします。次数 c の木構造 L ステップでグラフ全体がカバーできると考えます。 c<sup>L</sup> = n から、L = log n / log c になります。
| |
| − |
| |
| − | 連結性 ... ERグラフ全体が連結であるためには、グラフ進化の考察から次数は O(log n) 以上必要です。
| |
Revision as of 11:36, 6 August 2016
ここでは頂点がすべて連結した無向グラフを扱います。
歴史と参考図書
- Erdős P, Rényi A. "On Random Graphs. I.". Publicationes Mathematicae 6:290–297, 1959
- Erdős P, Rényi A. "The Evolution of Random Graphs". Publ. Math. Inst. Hung. Acad. Sci 5:17–61, 1960
- Bollobás B. Random Graphs (2nd ed.), Cambridge University Press, 2001
- Durrett R. Random Graph Dynamics, Cambridge University Press, 2004
Erdős–Rényiグラフ
全ての頂点間に一定の確率 p で独立に辺を作成してできるランダムグラフをErdős–Rényi (ER) グラフと呼びます。各頂点に注目してみると n -1 点に対して確率 p で辺を張るため、その次数は二項分布
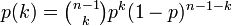
に従います。
ERモデルにおいて、辺の数を正確に N 本とする場合を考えることもできます。n 頂点からランダムに2つを選び、その間に辺を作成するプロセスを正確に N 回繰り返します。(ランダムに頂点を選ぶ回数は m = 2 N。)これは次数の期待値が p = 2 N / n(n -1) のERグラフにおいて、たまたま辺数が N となった場合に相当します。
次数の分布
各頂点についてみると、n -1 点に対して確率 p で辺を張るため平均次数は ( n -1) p です。
次数分布は二項分布になりますが、このままだと n を大きくすればいくらでも次数の大きな頂点が存在してしまいます。
しかし、現実のネットワークでは次数に上限がある場合がほとんどです。
そのため、サイズがどんなに大きくなっても各頂点の次数は平均的に一定値という仮定をします。
n → ∞, p → 0、 (n - 1) p → c (正定数)
このとき、二項分布はポアソン分布で近似できます。
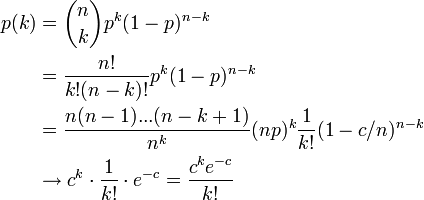
ここで c は次数 k の平均値 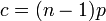 です。k が大きい場合、ポアソン分布は小さな値をとります。つまり、ハブ頂点はできにくくなります。
です。k が大きい場合、ポアソン分布は小さな値をとります。つまり、ハブ頂点はできにくくなります。
ネットワークの進化
次数の平均値 c = ( n -1) p を変化させて生じるグラフ形状の違いを検証します。
生成される辺数の期待値は pn (n -1) / 2 = cn/ 2 になります。n を無限大にしたとき、この値が 0 に近づくのでネットワークのサイズに対してほとんど辺を持たないことになります。
上と同じ理由で、ネットワーク全体で辺が定数本だけ作られるネットワークになります。ほとんどの辺がばらばらに存在します。
各頂点が一定数の辺を持つことを意味します。 ちょうど c = 1 だと二部グラフのマッチングです。c = 2 だと閉路の集合になります。
各頂点が持つ辺の本数(の期待値)が c なので、c < 1 のときは連結部分の大きさが高々 log n 程度にしかなりません。しかし c > 1 としたとたん、繋がっていく確率のほうが高くなります。その半径 (diameter) を k とおくと ck = n まで成長できるので k = log n / log c です。
詳細な解析によると、臨界点にあたる c = 1 では連結部分のサイズが O (n 2/3) になることが知られています。
全体が連結になります。ある頂点が辺を全く持たない確率を考えると
(1 - p)n - 1 = { ( 1 - c /(n - 1))(n - 1)/c }c <= e-c。したがって、そのような頂点がグラフ中に全く存在しない場合の上限は ne-c となります。これを 0 に収束させるには例えば c >= 2 log n で十分です。このとき孤立点は消滅しています。
- 相転移
上でみたように、次数の平均値が 1 をこえると急に連結成分のサイズが大きくなり、 log n に達すると全体が連結になります。
こうした点を、相転移点と呼びます。