Aritalab:Lecture/Bioinformatics/Homology
配列の相同性
進化の観点から似ている配列どうしを相同である (homologous) といいます。配列の相同性 (homology) という概念は、単なる類似性 (similarity) とは異なります。進化的に関係なくたまたま似ている場合は、相同であるとは言いません。配列比較をおこなうときに、生物学的に意味のある類似性を見出すことは重要なテーマです。
以下の 2 つのDNA配列 (27塩基) は相同でしょうか?
| g | c | t | a | g | g | a | t | c | a | c | g | g | c | c | a | t | g | g | c | a | a | g | c | g | c | g |
| a | a | t | t | g | a | a | g | g | a | t | t | g | c | t | c | g | g | a | t | a | a | t | c | g | c | c |
2 つの塩基がランダムだとすると、DNA配列は 1/4 の確率で一致し、3/4 の確率で不一致になります。ですから 12 塩基が一致するのはランダムな配列よりも似ているように思えます。ただし、上の揃え方では連続して一致する部分配列は長くても 3 つしか続きません。これを似ていると言ってよいのでしょうか。ここでは、相同性を判断するための様々な「指標」を考えましょう。
配列の組成、GC含量
配列がランダムであるかどうかの単純な指標は、塩基の組成をみることです。例1 の塩基配列組成は以下のようになっています。
|
|
長さが 27 塩基の場合、a, c, g, t のそれぞれは 6 ∼ 8 個ずつありそうなものですが、上の配列は t が 3 個しかありません。これはどのくらいの確率で生じる現象なのでしょうか。話を簡単にするため、gc 含量という概念を使います。塩基配列は常に相補鎖があり、a は t と、g は c と対合しています。ですから単純に t だけの量を議論するのは不正確で、a + t, g + c を比較します。
全部で 27 箇所に、at または gc がランダムに配置されるとき、平均して 13 または 14 箇所が at になると考えられます。では at が 9 箇所にしか現れない確率は、その平均的な場合に比較してどれくらい珍しいのでしょうか。それは二項係数の比を求めればわかります。
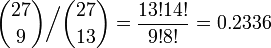
ランダムな配列と大差ないことがわかります。同様の計算で、もし at が 5 箇所にしか出てこない場合は、平均的な場合に比して 0.004 だとわかります。(稀といえるでしょう。)
最長共通部分列
配列が与えられた時、共通して現れる部分文字列(連続する必要はない)のうち、最長のものを求めるアルゴリズムを考えてみましょう。27 文字の例1は長いので、ここでは