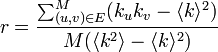Aritalab:Lecture/NetworkBiology/Degree Distribution
m (→隣接点の次数分布) |
m (→次数相関) |
||
| Line 24: | Line 24: | ||
生態系のような生物学ネットワークでは負の相関を持つ (disassortative) と考えられます。 | 生態系のような生物学ネットワークでは負の相関を持つ (disassortative) と考えられます。 | ||
| − | + | 隣接点の平均次数は、次数分布や頂点の次数 ''k'' によらず一定値となります。 | |
| − | <math> \ | + | <math> \sum_{j\not=k} j p(j|k) = \frac{\langle k^2 \rangle - \langle k \rangle}{\langle k \rangle}</math> |
| − | 全頂点の次数が同じ時 <k<sup>2</sup>> = <k><sup>2</sup> となるので、隣接点の平均次数は <k> | + | 全頂点の次数が同じ時 <k<sup>2</sup>> = <k><sup>2</sup> となるので、隣接点の平均次数は <k> - 1 になります(たどってくる辺を除いた場合)。また次数の偏りが大きくハブが存在する場合、隣接点の平均次数は <k> を大きくうわまわります。(つまり隣にハブが来やすくなる。)次数がポアソン分布に従う場合、<k<sup>2</sup>> = <k><sup>2</sup> + <k> が成り立ちます。ポアソン分布の場合は、たどる辺をちょ差し引くと、ちょうど隣接点も次数 <k> です。 |
===計算法=== | ===計算法=== | ||
Revision as of 15:40, 3 August 2016
Contents |
次数分布
次数 k が全頂点の中で占める割合 p(k) を次数分布といいます。確率分布なので総和は 1 です。
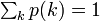
その平均値を、平均次数といい <k> = Σ k p(k) と書きます。
隣接点の次数分布
隣接する頂点の次数を 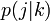 と書きましょう。ここで次数 k の頂点に隣接する頂点の次数が j です。
すると次の式から、次数が j の頂点は相対的に j / <k> だけ、隣にきやすいはずです。
と書きましょう。ここで次数 k の頂点に隣接する頂点の次数が j です。
すると次の式から、次数が j の頂点は相対的に j / <k> だけ、隣にきやすいはずです。
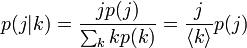
隣の頂点には、ハブが来やすいことがわかります。その来やすさは、頂点の次数に正比例します。この次数の平均値を求めるときは、k から j をたどる辺 1 本ぶんを最初に引いておきましょう。
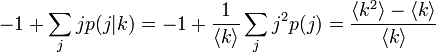
次数相関
隣接する頂点どうしの次数が似る度合いを次数相関といいます。 辺がランダムに張られる場合は次数相関は 0 になりますが、映画俳優の競演関係といったネットワークはハブどうしが隣接する、つまり正の相関を持つ (assortative) ことが知られています。 生態系のような生物学ネットワークでは負の相関を持つ (disassortative) と考えられます。
隣接点の平均次数は、次数分布や頂点の次数 k によらず一定値となります。
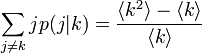
全頂点の次数が同じ時 <k2> = <k>2 となるので、隣接点の平均次数は <k> - 1 になります(たどってくる辺を除いた場合)。また次数の偏りが大きくハブが存在する場合、隣接点の平均次数は <k> を大きくうわまわります。(つまり隣にハブが来やすくなる。)次数がポアソン分布に従う場合、<k2> = <k>2 + <k> が成り立ちます。ポアソン分布の場合は、たどる辺をちょ差し引くと、ちょうど隣接点も次数 <k> です。
計算法
次数相関 r をピアソンの相関係数に従って定義しましょう。M 本ある辺の両端点 u, v の次数をそれぞれ ku, ku とおきます。相関係数の分子は ku, kv の平均からの差分を計算します。 分母は ku と kv の標準偏差の積ですが、実際には分散を計算します。