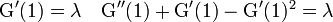Aritalab:Lecture/Basic/Probability Generating Function
From Metabolomics.JP
< Aritalab:Lecture | Basic(Difference between revisions)
m |
|||
| Line 1: | Line 1: | ||
{{Lecture/Header}} | {{Lecture/Header}} | ||
| + | |||
| + | ==まとめ== | ||
| + | |||
| + | 確率母関数 <math>G_X(z)</math> が与えられれば | ||
| + | * 平均 <math>E(X) = G_X'(1) \,</math> | ||
| + | * 分散 <math>V(X) = G_X''(1) + G_X'(1) - G_X'(1)^2 \,</math> | ||
| + | |||
==確率母関数== | ==確率母関数== | ||
| − | ある確率分布<math> | + | ある確率分布 '''Pr'''<math>(X=k)</math> の確率母関数 (probability generating function または pgf) を以下のように定義します。 |
<math>\textstyle G_X(z) = \Sigma_{k=0}^{\infty}\mbox{Pr}(X=k)z^k</math> | <math>\textstyle G_X(z) = \Sigma_{k=0}^{\infty}\mbox{Pr}(X=k)z^k</math> | ||
| − | 確率<math>\mbox{Pr}(X=k)</math>は全て正の値で''k'' | + | 確率<math>\mbox{Pr}(X=k)</math>は全て正の値で ''k'' について全て足しあわせると 1 になります。 |
<math>\textstyle G_X(1) | <math>\textstyle G_X(1) | ||
| Line 13: | Line 20: | ||
= \Sigma_{k=0}^{\infty}\mbox{Pr}(X=k) = 1</math> | = \Sigma_{k=0}^{\infty}\mbox{Pr}(X=k) = 1</math> | ||
| − | 逆に係数が非負で<math>G(1) = 1</math>であるようなべき級数<math>G(z)</math> | + | 逆に係数が非負で <math>G(1) = 1</math> であるようなべき級数 <math>G(z)</math> があれば、それは何らかの確率母関数といいます。 |
===平均と分散=== | ===平均と分散=== | ||
| − | + | 確率母関数を使うと平均と分散の計算が容易にできます。 | |
<math>\textstyle | <math>\textstyle | ||
| Line 41: | Line 48: | ||
==一様分布== | ==一様分布== | ||
| − | ''n''次の一様分布(uniform distribution)とは確率変数が<math>{0, 1, \ldots, n-1}</math>の値を確率<math>1/n</math> | + | ''n''次の一様分布 (uniform distribution) とは確率変数が<math>{0, 1, \ldots, n-1}</math>の値を確率<math>1/n</math>でとるものです。 |
<math>\textstyle | <math>\textstyle | ||
| Line 47: | Line 54: | ||
</math> | </math> | ||
| − | + | 確率母関数は以下の等比級数になります。 | |
<math>\textstyle | <math>\textstyle | ||
\mbox{U}_n(z) = \frac{1}{n}(1 + z + \cdots + z^{n-1}) = \frac{1}{n}\frac{1-z^n}{1-z} | \mbox{U}_n(z) = \frac{1}{n}(1 + z + \cdots + z^{n-1}) = \frac{1}{n}\frac{1-z^n}{1-z} | ||
</math> | </math> | ||
| − | この式は<math>1-z</math>を分母に含んでしまうため、<math>\mbox{U}_n'(1)</math>や<math>\mbox{U}_n''(1)</math> | + | この式は<math>1-z</math>を分母に含んでしまうため、<math>\mbox{U}_n'(1)</math>や<math>\mbox{U}_n''(1)</math>を求める際に不都合です。そこでテイラーの定理を応用します。 |
<math> | <math> | ||
| Line 58: | Line 65: | ||
</math> | </math> | ||
| − | この係数、つまり<math>G(z)</math> | + | この係数、つまり<math>G(z)</math>の導関数を以下の式と見比べます。 |
<math> | <math> | ||
| Line 85: | Line 92: | ||
==ポアソン分布== | ==ポアソン分布== | ||
| − | ポアソン分布とは単位時間中に平均<math>\lambda</math>回発生する事象がちょうど''k'' | + | ポアソン分布とは単位時間中に平均 <math>\lambda</math> 回発生する事象がちょうど ''k'' 回発生する確率をあらわしています。 |
<math>\textstyle | <math>\textstyle | ||
Revision as of 19:38, 15 June 2011
| Wiki Top | Up one level | レポートの書き方 | Arita Laboratory |
|
まとめ
確率母関数 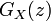 が与えられれば
が与えられれば
- 平均
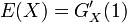
- 分散
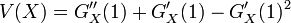
確率母関数
ある確率分布 Pr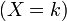 の確率母関数 (probability generating function または pgf) を以下のように定義します。
の確率母関数 (probability generating function または pgf) を以下のように定義します。
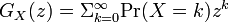
確率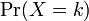 は全て正の値で k について全て足しあわせると 1 になります。
は全て正の値で k について全て足しあわせると 1 になります。
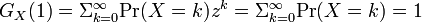
逆に係数が非負で 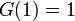 であるようなべき級数
であるようなべき級数 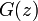 があれば、それは何らかの確率母関数といいます。
があれば、それは何らかの確率母関数といいます。
平均と分散
確率母関数を使うと平均と分散の計算が容易にできます。
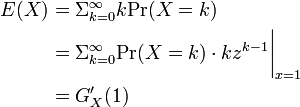
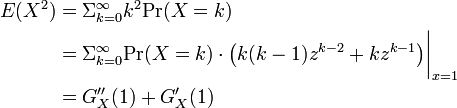
したがって
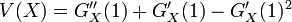
一様分布
n次の一様分布 (uniform distribution) とは確率変数が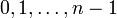 の値を確率
の値を確率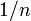 でとるものです。
でとるものです。
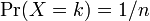
確率母関数は以下の等比級数になります。
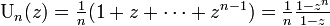
この式は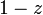 を分母に含んでしまうため、
を分母に含んでしまうため、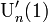 や
や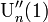 を求める際に不都合です。そこでテイラーの定理を応用します。
を求める際に不都合です。そこでテイラーの定理を応用します。
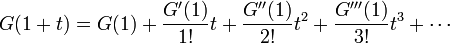
この係数、つまりの導関数を以下の式と見比べます。
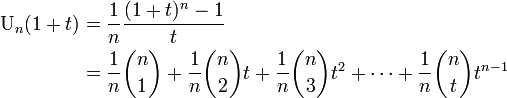
ここから
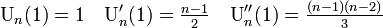
平均と分散は
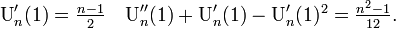
ポアソン分布
ポアソン分布とは単位時間中に平均 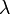 回発生する事象がちょうど k 回発生する確率をあらわしています。
回発生する事象がちょうど k 回発生する確率をあらわしています。
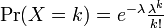
確率母関数は
Failed to parse (lexing error): \textstyle \begin{align} G(z) &= \Sigma_{k=0}^{\infty} e^{-\lambda}\frac{\lambda^k}{k!} z^k = e^{-\lambda}\Sigma_{k=0}^{\infty}\frac{(\lambda z)^k}{k!} = e^{-\lambda} e^{\lambda z} \\ &= e^{\lambda (z-1)} \end{align}
平均と分散は