Aritalab:Lecture/NetworkBiology/Link Analysis
Contents |
歴史
- 1998 Jan: J. KleinbergがHITSアルゴリズムを発表(9th ACM-SIAM DA)
- 1998 Apr: S. Brin, L. PageがPageRankを発表(7th WWW)
Centrality
無向グラフにおいて、頂点のネットワーク中心への近さを示す尺度を中心度(centrality)という。いずれの値も0-1の間をとるように正規化する。有向グラフでも定義できるが、次に述べるprestigeを使った方がよい。
- Degree centrality ... 辺数が多い点を中心と考える。
- Closeness centrality ... 全頂点への平均最短距離が短い点を中心と考える。
- Betweenness centrality ... 全頂点間の最短経路に多く使われる点を中心と考える。同じ値で辺のbetweennessも定義できる。
| Name | Undirected | Directed |
|---|---|---|
| Degree | 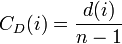 |
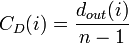
|
|
| ||
| Closeness | 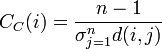
| |
| Betweenness | 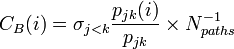
ただしj,kはiと異なる頂点。iを除いた最短経路の本数は無向で | |
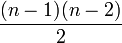 、有向で
、有向で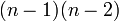 。
。
Prestige
有向グラフにおいて頂点の傑出具合を測る尺度を傑出度(prestige)という。
- Degree prestige ... 多くの入力辺がある点を傑出していると考える。
- Proximity prestige ... より多くの頂点から到達できる点を傑出していると考える。Degree prestigeの拡張になっている。
- Rank prestige ... 高いランクの頂点に指されている頂点もランクが高いと考える。
| Name | |
|---|---|
| Degree | 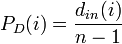
|
| Proximity | 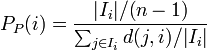
|
| Rank | 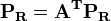
|
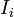 はiより到達できる頂点集合
はiより到達できる頂点集合
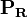 は長さnの縦ベクトル、
は長さnの縦ベクトル、共引用と書誌結合
文献計量学 (Bibliometrics) において使われる概念に共引用 (co-citation) と書誌結合 (bibliographic coupling) がある。
文献iがjを引用するときij成分を1、それ以外は0と定義した正方行列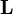 (引用行列)を考えたとき、
文献iとjを同時に引用する文献の数は
(引用行列)を考えたとき、
文献iとjを同時に引用する文献の数は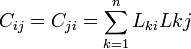 とあらわされる。
とあらわされる。
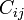 を要素とする正方行列
を要素とする正方行列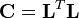 を共引用行列と呼ぶ。
を共引用行列と呼ぶ。
書誌結合関係とは共引用関係と対を成す概念である。
文献iとjがともに同じ文献を引用するとき、iとjは書誌結合関係にあるという。文献iとjに同時に引用される文献の数は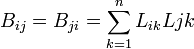 とあらわされる。
とあらわされる。
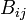 を要素とする正方行列
を要素とする正方行列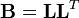 を書誌結合行列と呼ぶ。
を書誌結合行列と呼ぶ。
PageRank
Rank prestigeにおいて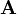 を単なる隣接行列ではなく各頂点の次数(degree)でスケーリングした値、すなわち
を単なる隣接行列ではなく各頂点の次数(degree)でスケーリングした値、すなわち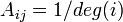 としたものをPageRankと呼ぶ。
つまり、行列を、ウェブページを訪れるユーザがページ内のリンクを等確率でクリックして次ページに移動するマルコフ過程の遷移行列と考えたとき、PageRankはその定常分布に相当する。
としたものをPageRankと呼ぶ。
つまり、行列を、ウェブページを訪れるユーザがページ内のリンクを等確率でクリックして次ページに移動するマルコフ過程の遷移行列と考えたとき、PageRankはその定常分布に相当する。
しかしこのままでは実用上以下の問題点がある。
- マルコフ過程の定常分布は、全ての状態が再帰的 (recurrent、つまり有限のステップで同じ状態に戻ってくることが可能)でないと求まらない。つまり、遷移の過程でどのページからも抜け出せないとランクを付与できないページが生じる。
- ページ間のネットワークが強連結(strongly connected)でないと定常分布における確率が0となる頂点が生じてしまう。
- 遷移過程に周期性が存在すると、定常分布として収束しない。
これらの問題点を回避するため、ユーザはリンク先の無いページからは他の全ページに等確率で移動し、リンク先を持つページからもある一定確率でランダムに他ページに移動すると仮定する。つまり
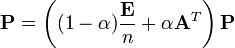 ここで行列
ここで行列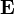 は要素が全て1の正方行列。またパラメータαをdamping factorと呼び、d=0.85程度が用いられる。
は要素が全て1の正方行列。またパラメータαをdamping factorと呼び、d=0.85程度が用いられる。
利点と欠点
ページランクはパラメータを持たない固定値のため事前に計算しておくことが可能。スパムに対しても頑健。 ただ、問い合わせの内容を一切考慮しないのは欠点ともいえる。
HITS
Hypertext Induced Topic Searchはオーソリティおよびハブと呼ばれる二種の頂点集合からなる二部グラフを求めるアルゴリズム。
オーソリティとは入力辺を多く持つページで多くのハブからリンクされる。
ハブとは出力辺を多く持つページで多くのオーソリティへリンクする。
各頂点におけるオーソリティとハブのスコアをあらわす縦ベクトルはそれぞれ
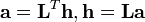 とあらわされる。
これは代入すれば
とあらわされる。
これは代入すれば
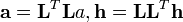 であり、それぞれ共引用と書誌結合関係に対応する。
つまりオーソリティ度は共引用行列の固有値、ハブ度は書誌結合行列の固有値になる。
であり、それぞれ共引用と書誌結合関係に対応する。
つまりオーソリティ度は共引用行列の固有値、ハブ度は書誌結合行列の固有値になる。
クエリをもらったらまずランクの高いページを200程度集め、そのページからリンクされる、またリンクするページを増やして初期集合を形成する。この集合から作成した引用行列\mathbf{L}を単位ベクトルを初期値とした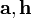 に収束するまで掛け算し、値を出力する。
に収束するまで掛け算し、値を出力する。
利点と欠点
初期集合を形成する際に、余計なページを含むことでTopic driftとよばれるテーマの移動が起こってしまう。またスパムに対して弱い(ハブを簡単に偽装できる)。そのかわり、与えられたキーワードについて関連する重要ページを発見できる利点を持つ。
ウェブコミュニティ
ハブとオーソリティの関係のように、特定のトピックについて密に関連したページ集合をコミュニティと呼ぶ。(定義はさまざまある。) いくつかの例を挙げる。
- 二部グラフコミュニティ ... 完全二部グラフを探すアルゴリズムで探索できる (HITS 1998)
- 最大流コミュニティ ... 最大流アルゴリズムを用いてボトルネックを探し、ネットワークを切断してゆくことで探索できる (Flake et al. IEEE Computer 35(3) 2002)
- 辺betweennessコミュニティ ... betweennessが大きい辺から順番に除いていく
いずれもコミュニティの定義がはっきりしないので適当な時点でイテレーションを停止するしかない。