Aritalab:Lecture/NetworkBiology/Erdos-Renyi Model
| Line 1: | Line 1: | ||
ここでは頂点がすべて連結した無向グラフを扱う。 | ここでは頂点がすべて連結した無向グラフを扱う。 | ||
| − | =歴史と参考図書= | + | ==歴史と参考図書== |
* Erdős P, Rényi A. "On Random Graphs. I.". Publicationes Mathematicae 6:290–297, 1959 | * Erdős P, Rényi A. "On Random Graphs. I.". Publicationes Mathematicae 6:290–297, 1959 | ||
* Erdős P, Rényi A. "The Evolution of Random Graphs". Publ. Math. Inst. Hung. Acad. Sci 5:17–61, 1960 | * Erdős P, Rényi A. "The Evolution of Random Graphs". Publ. Math. Inst. Hung. Acad. Sci 5:17–61, 1960 | ||
| Line 7: | Line 7: | ||
* Durrett R. Random Graph Dynamics, Cambridge University Press, 2004 | * Durrett R. Random Graph Dynamics, Cambridge University Press, 2004 | ||
| − | =ネットワークの指標:<math>C</math>と<math>L</math>= | + | ==ネットワークの指標:<math>C</math>と<math>L</math>== |
ネットワーク全体についての尺度として、クラスター係数<math>C</math>と平均頂点間距離<math>L</math>を紹介する。 | ネットワーク全体についての尺度として、クラスター係数<math>C</math>と平均頂点間距離<math>L</math>を紹介する。 | ||
| − | ==クラスター係数== | + | ===クラスター係数=== |
クラスター係数は隣接する頂点間の辺の密度の平均値にあたる。まず各頂点<math>i</math>におけるクラスター係数<math>C_i</math>を以下のように定義する。辺の長さはすべて1とする<math>|e|=1</math>。 | クラスター係数は隣接する頂点間の辺の密度の平均値にあたる。まず各頂点<math>i</math>におけるクラスター係数<math>C_i</math>を以下のように定義する。辺の長さはすべて1とする<math>|e|=1</math>。 | ||
:<math>\textstyle C_i=\frac{2}{deg(i)(deg(i)-1)} \sum_{j,k \in neighbor(i)} |e_{jk}|</math> | :<math>\textstyle C_i=\frac{2}{deg(i)(deg(i)-1)} \sum_{j,k \in neighbor(i)} |e_{jk}|</math> | ||
| Line 16: | Line 16: | ||
:<math>\textstyle C =\frac{1}{n} \sum^{n}_{i=1}C_i</math> | :<math>\textstyle C =\frac{1}{n} \sum^{n}_{i=1}C_i</math> | ||
| − | ==平均頂点間距離== | + | ===平均頂点間距離=== |
平均頂点間距離はその字のごとく全頂点間の最短路の平均値にあたる。ここでは頂点<math>i, j</math>間の最短経路を<math>p_{ij}</math>と書く。各点に注目する場合は、距離<math>L</math>以内にある頂点数を数えることで求められる。 | 平均頂点間距離はその字のごとく全頂点間の最短路の平均値にあたる。ここでは頂点<math>i, j</math>間の最短経路を<math>p_{ij}</math>と書く。各点に注目する場合は、距離<math>L</math>以内にある頂点数を数えることで求められる。 | ||
:<math>\textstyle L=\frac{1}{n} \sum_{i,j\in G}|p_{ij}|</math> | :<math>\textstyle L=\frac{1}{n} \sum_{i,j\in G}|p_{ij}|</math> | ||
| − | ==様々なグラフにおける<math>C</math>と<math>L</math>== | + | ===様々なグラフにおける<math>C</math>と<math>L</math>=== |
| − | ===完全グラフ=== | + | ====完全グラフ==== |
全ての頂点間に辺を持つグラフは<math>C=L=1</math>。 | 全ての頂点間に辺を持つグラフは<math>C=L=1</math>。 | ||
| − | ===格子=== | + | |
| + | ====格子==== | ||
平面の場合は三角格子、正方格子が考えられる。特に、<math>d</math>次元空間において辺の長さが単位距離の格子を'''Z'''<sup>d</sup>と書く。 | 平面の場合は三角格子、正方格子が考えられる。特に、<math>d</math>次元空間において辺の長さが単位距離の格子を'''Z'''<sup>d</sup>と書く。 | ||
:例. '''Z'''<sup>2</sup>において、<math>deg(i)=2d</math> | :例. '''Z'''<sup>2</sup>において、<math>deg(i)=2d</math> | ||
| Line 30: | Line 31: | ||
:例. '''Z''''<sup>d</sup>のクラスター係数は<math>\textstyle C=\frac{3(a-1)}{2(2a-1)}</math>、平均頂点間距離は<math>\textstyle L=\sqrt[d]{n}/a</math> | :例. '''Z''''<sup>d</sup>のクラスター係数は<math>\textstyle C=\frac{3(a-1)}{2(2a-1)}</math>、平均頂点間距離は<math>\textstyle L=\sqrt[d]{n}/a</math> | ||
| − | ===木=== | + | ====木==== |
簡単のため全頂点が同じ次数を持つ木を考える。中心の頂点<math>v_0</math>を根(root)と呼ぶ。木はその定義よりサイクルを持たないので<math>C=0</math>。また平均頂点間距離は、距離L以内にある頂点を数えることで求められる。 | 簡単のため全頂点が同じ次数を持つ木を考える。中心の頂点<math>v_0</math>を根(root)と呼ぶ。木はその定義よりサイクルを持たないので<math>C=0</math>。また平均頂点間距離は、距離L以内にある頂点を数えることで求められる。 | ||
:<math>n = 1 + d + d(d-1) + ... + d(d-1)^L = 1 +d (1-(d-1)^{L+1})/(1-(d-1))</math>∝<math>(d-1)^{L+1}</math> | :<math>n = 1 + d + d(d-1) + ... + d(d-1)^L = 1 +d (1-(d-1)^{L+1})/(1-(d-1))</math>∝<math>(d-1)^{L+1}</math> | ||
| Line 36: | Line 37: | ||
:<math>\textstyle L=\propto \frac{\log n}{\log (d-1)} \propto \log n</math> | :<math>\textstyle L=\propto \frac{\log n}{\log (d-1)} \propto \log n</math> | ||
| − | =Erdős–Rényiグラフ= | + | ==Erdős–Rényiグラフ== |
全ての頂点間に一定の確率<math>p</math>で独立に辺を作成してできるランダムグラフをErdős–Rényiグラフと呼ぶ。各頂点に注目してみると<math>n-1</math>点に対して確率<math>p</math>で辺を張るため、次数は二項分布<math>{}_{n-1}\mbox{C}_k p^k(1-p)^{n-1-k}</math>に従う。すなわち次数の平均は<math>c = (n-1)p</math>と書ける。 | 全ての頂点間に一定の確率<math>p</math>で独立に辺を作成してできるランダムグラフをErdős–Rényiグラフと呼ぶ。各頂点に注目してみると<math>n-1</math>点に対して確率<math>p</math>で辺を張るため、次数は二項分布<math>{}_{n-1}\mbox{C}_k p^k(1-p)^{n-1-k}</math>に従う。すなわち次数の平均は<math>c = (n-1)p</math>と書ける。 | ||
| − | ==ネットワークの進化== | + | ===ネットワークの進化=== |
次数の平均値<math>c</math>を変化させて生じるグラフ形状の違いを検証しよう。 | 次数の平均値<math>c</math>を変化させて生じるグラフ形状の違いを検証しよう。 | ||
;<math>\textstyle c \le \frac{1}{n^2} </math> | ;<math>\textstyle c \le \frac{1}{n^2} </math> | ||
| Line 56: | Line 57: | ||
全体が連結になる。ある頂点が辺を全く持たない確率は<math>\textstyle (1-p)^{n-1}=((1-\frac{c}{n-1})^{\frac{n-1}{c}})^{c} \leq e^{-c}</math>。したがって、そのような頂点がグラフ中に存在しない確率の上限は<math>ne^{-c}</math>となる。これを0に収束させるには例えば<math>c \geq 2 \log n</math>で十分である。このとき孤立点が消滅する。 | 全体が連結になる。ある頂点が辺を全く持たない確率は<math>\textstyle (1-p)^{n-1}=((1-\frac{c}{n-1})^{\frac{n-1}{c}})^{c} \leq e^{-c}</math>。したがって、そのような頂点がグラフ中に存在しない確率の上限は<math>ne^{-c}</math>となる。これを0に収束させるには例えば<math>c \geq 2 \log n</math>で十分である。このとき孤立点が消滅する。 | ||
| − | ==辺の数を固定するモデル== | + | ===辺の数を固定するモデル=== |
辺の数を正確に<math>N</math>本とする場合を考えよう。<math>n</math>頂点からランダムに2つを選び、その間に辺を作成するプロセスを正確に<math>N</math>回繰り返す。(ランダムに頂点を選ぶ回数は<math>m = 2N</math>。)これは次数の期待値が<math>p=2N/n(n-1)</math>のERグラフにおいて、ちょうど辺数が<math>N</math>となった場合に相当する。 | 辺の数を正確に<math>N</math>本とする場合を考えよう。<math>n</math>頂点からランダムに2つを選び、その間に辺を作成するプロセスを正確に<math>N</math>回繰り返す。(ランダムに頂点を選ぶ回数は<math>m = 2N</math>。)これは次数の期待値が<math>p=2N/n(n-1)</math>のERグラフにおいて、ちょうど辺数が<math>N</math>となった場合に相当する。 | ||
| − | ==ネットワークの特徴== | + | ===ネットワークの特徴=== |
;クラスター係数 | ;クラスター係数 | ||
:辺が張られる確率は全て独立なので<math>C(p)=p \simeq c /n</math>。これは<math>K_3</math>や<math>K_4</math>をあまり含まないことを意味している。 | :辺が張られる確率は全て独立なので<math>C(p)=p \simeq c /n</math>。これは<math>K_3</math>や<math>K_4</math>をあまり含まないことを意味している。 | ||
Revision as of 13:55, 2 June 2010
ここでは頂点がすべて連結した無向グラフを扱う。
Contents |
歴史と参考図書
- Erdős P, Rényi A. "On Random Graphs. I.". Publicationes Mathematicae 6:290–297, 1959
- Erdős P, Rényi A. "The Evolution of Random Graphs". Publ. Math. Inst. Hung. Acad. Sci 5:17–61, 1960
- Bollobás B. Random Graphs (2nd ed.), Cambridge University Press, 2001
- Durrett R. Random Graph Dynamics, Cambridge University Press, 2004
ネットワークの指標: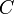 と
と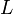
ネットワーク全体についての尺度として、クラスター係数と平均頂点間距離を紹介する。
クラスター係数
クラスター係数は隣接する頂点間の辺の密度の平均値にあたる。まず各頂点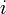 におけるクラスター係数
におけるクラスター係数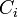 を以下のように定義する。辺の長さはすべて1とする
を以下のように定義する。辺の長さはすべて1とする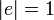 。
。
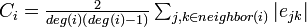
グラフ全体のクラスター係数はその平均値になる。
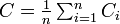
平均頂点間距離
平均頂点間距離はその字のごとく全頂点間の最短路の平均値にあたる。ここでは頂点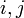 間の最短経路を
間の最短経路を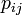 と書く。各点に注目する場合は、距離以内にある頂点数を数えることで求められる。
と書く。各点に注目する場合は、距離以内にある頂点数を数えることで求められる。
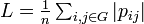
様々なグラフにおけると
完全グラフ
全ての頂点間に辺を持つグラフは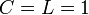 。
。
格子
平面の場合は三角格子、正方格子が考えられる。特に、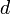 次元空間において辺の長さが単位距離の格子をZdと書く。
次元空間において辺の長さが単位距離の格子をZdと書く。
- 例. Z2において、
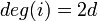
定義のままだとクラスター係数が0になって面白くないので、最短距離が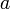 以下の点には全て辺を張るバリエーションZ'dを考えよう。
以下の点には全て辺を張るバリエーションZ'dを考えよう。
- 例. Z'dのクラスター係数は
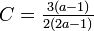 、平均頂点間距離は
、平均頂点間距離は![\textstyle L=\sqrt[d]{n}/a](/mediawiki/images/math/f/5/8/f583b41db535b1a73d0d831b87ea2808.png)
木
簡単のため全頂点が同じ次数を持つ木を考える。中心の頂点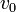 を根(root)と呼ぶ。木はその定義よりサイクルを持たないので
を根(root)と呼ぶ。木はその定義よりサイクルを持たないので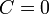 。また平均頂点間距離は、距離L以内にある頂点を数えることで求められる。
。また平均頂点間距離は、距離L以内にある頂点を数えることで求められる。
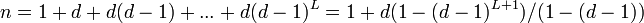 ∝
∝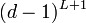
すなわち
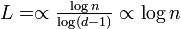
Erdős–Rényiグラフ
全ての頂点間に一定の確率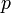 で独立に辺を作成してできるランダムグラフをErdős–Rényiグラフと呼ぶ。各頂点に注目してみると
で独立に辺を作成してできるランダムグラフをErdős–Rényiグラフと呼ぶ。各頂点に注目してみると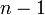 点に対して確率で辺を張るため、次数は二項分布
点に対して確率で辺を張るため、次数は二項分布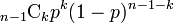 に従う。すなわち次数の平均は
に従う。すなわち次数の平均は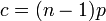 と書ける。
と書ける。
ネットワークの進化
次数の平均値 を変化させて生じるグラフ形状の違いを検証しよう。
を変化させて生じるグラフ形状の違いを検証しよう。
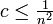
辺の生成される確率が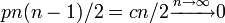 になるため、辺を持たない。
になるため、辺を持たない。
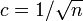
辺があったとしても木にしかならない。
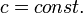
各頂点が定数本の辺を持ちはじめる。
- ちょうど
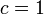 だと二部グラフのマッチング、
だと二部グラフのマッチング、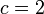 だと閉路の集合になる。
だと閉路の集合になる。
- 各頂点が持つ辺の本数(の期待値)がなので、
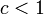 のとき連結部分の大きさは高々
のとき連結部分の大きさは高々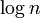 程度にしかならない。しかし
程度にしかならない。しかし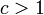 の場合繋がっていく確率のほうが高く、その半径(diameter)を
の場合繋がっていく確率のほうが高く、その半径(diameter)を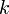 とおくと
とおくと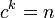 まで成長できる。このとき
まで成長できる。このとき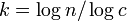 。
。
- 詳細な解析によると、臨界点にあたるでは連結部分のサイズが
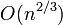 になることが知られている。
になることが知られている。
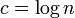
全体が連結になる。ある頂点が辺を全く持たない確率は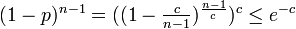 。したがって、そのような頂点がグラフ中に存在しない確率の上限は
。したがって、そのような頂点がグラフ中に存在しない確率の上限は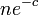 となる。これを0に収束させるには例えば
となる。これを0に収束させるには例えば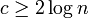 で十分である。このとき孤立点が消滅する。
で十分である。このとき孤立点が消滅する。
辺の数を固定するモデル
辺の数を正確に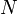 本とする場合を考えよう。
本とする場合を考えよう。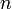 頂点からランダムに2つを選び、その間に辺を作成するプロセスを正確に回繰り返す。(ランダムに頂点を選ぶ回数は
頂点からランダムに2つを選び、その間に辺を作成するプロセスを正確に回繰り返す。(ランダムに頂点を選ぶ回数は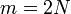 。)これは次数の期待値が
。)これは次数の期待値が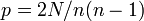 のERグラフにおいて、ちょうど辺数がとなった場合に相当する。
のERグラフにおいて、ちょうど辺数がとなった場合に相当する。
ネットワークの特徴
- クラスター係数
- 辺が張られる確率は全て独立なので
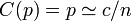 。これは
。これは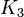 や
や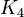 をあまり含まないことを意味している。
をあまり含まないことを意味している。
- 平均頂点間距離
- 各頂点が持つ辺の期待値をとして
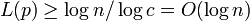 。
。
- 連結性
- Erdős–Rényiグラフ全体が連結であるためには次数が
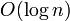 以上必要。
以上必要。