Aritalab:Lecture/JSBi/Test/Math
(→ポアソン分布) |
|||
| Line 20: | Line 20: | ||
共分散をXの標準偏差とYの標準偏差で割ったものが相関係数である。 | 共分散をXの標準偏差とYの標準偏差で割ったものが相関係数である。 | ||
:<math>Corr[X,Y] = Cov[X,Y] /(V[X]^{1/2}V[Y]^{1/2})</math> | :<math>Corr[X,Y] = Cov[X,Y] /(V[X]^{1/2}V[Y]^{1/2})</math> | ||
| − | |||
| − | === | + | ===ベイズ推定=== |
| − | + | ベイズの定理は以下のように表される。 | |
| − | :<math>P( | + | :<math>P(A|B) = P(B|A)P(A)/P(B)</math> |
| + | ここでP(A)を事前確率、P(A|B)を(Bが起きることを知った上でのAが起きる確率という意味の)事後確率と呼ぶ。 | ||
| + | <!--- | ||
| + | 参考 [http://ja.wikipedia.org/wiki/%E3%83%A2%E3%83%B3%E3%83%86%E3%82%A3%E3%83%BB%E3%83%9B%E3%83%BC%E3%83%AB%E5%95%8F%E9%A1%8C モンティ・ホール問題] | ||
| + | :3つの扉のうち1つだけに賞品が入っている。ただし扉は次のように2段階で選べる。 | ||
| + | まず回答者は3つの扉からどれか1つを選ぶ。 | ||
| + | 次に、答を知っている司会者が、選んでいない扉で賞品の入っていない扉1つを開けてみせる。ただし、回答者が当たりの扉を選んでいる場合は、残りの扉からランダムに1つを選んで開けるとする。このあと回答者は扉を1回選び直してもよい。 | ||
| + | 2で扉を換えるのと換えないのと、どちらが当る確率が高いか? | ||
| + | ---> | ||
=分布= | =分布= | ||
| − | |||
==正規分布== | ==正規分布== | ||
よく見る釣鐘型の分布。どんな分布でも、その中から要素をランダムに抽出して和をとったものの分布は、正規分布に近づく(中心極限定理)。期待値が0, 分散が1になるようにスケーリングしたものを標準正規分布といい、<math>N(0,1)</math>と書く。 | よく見る釣鐘型の分布。どんな分布でも、その中から要素をランダムに抽出して和をとったものの分布は、正規分布に近づく(中心極限定理)。期待値が0, 分散が1になるようにスケーリングしたものを標準正規分布といい、<math>N(0,1)</math>と書く。 | ||
| Line 62: | Line 68: | ||
==二項分布== | ==二項分布== | ||
| + | コイン投げをして表裏がでる回数を記録したときにできる分布。 | ||
| + | 離散的な分布だが、フェアなコインを30回程度投げると正規分布で非常によく近似できる。 | ||
| − | + | =統計・推定= | |
| − | = | + | 母集団から無作為に抽出された標本集団から、もとの母集団を統計的に推し量ることを推定という。 |
| − | + | ===回帰分析=== | |
| + | 従属変数(近似したい値、目的変数ともいう)と説明変数(近似に用いるデータ)の関係を統計的に推定することを回帰分析という。 | ||
| + | 1個の説明変数から1個の従属変数を予測する場合を単回帰、説明変数を複数用いる場合を重回帰という。 | ||
| + | 従属変数を<i>y</i>、説明変数を<i>x</i>とすると | ||
| + | :<math> y_i = a_{i1}x_{i1} + a_{i2}x_{i2} + ... a_{ij}x_{ij}</math> | ||
| + | の形でパラメータ<i>a_{ij}</i>を最小二乗法で決定する線形回帰が一般的。 | ||
==点推定と区間推定== | ==点推定と区間推定== | ||
標本の値から、母集団の平均値や分散を予測することを点推定(数値を点として予測)と呼び、その推定がどれ位ずれているかを区間推定と呼ぶ。 | 標本の値から、母集団の平均値や分散を予測することを点推定(数値を点として予測)と呼び、その推定がどれ位ずれているかを区間推定と呼ぶ。 | ||
Revision as of 12:56, 9 October 2010
Contents |
確率
平均
期待値とは、確率変数の取る値とその確率とをかけた総和である。フェアなサイコロのように全ての目が糖確率で出る場合は、目の数の期待値は(算術)平均に等しくなる。二つの確率変数X,Yがあったとき、和の平均は平均の和に等しい。
![E[X+Y]=E[X]+E[Y]](/mediawiki/images/math/b/2/8/b2878846b9242595fd3b6b27bb32c83b.png)
X,Yが独立のときに限り、積についても分配できる。
![E[XY]=E[X]E[Y]](/mediawiki/images/math/2/4/e/24e57b4c4766bb198576936fa4dd6e7e.png) (ただしX,Yは独立)
(ただしX,Yは独立)
分散
分散とは確率変数がとる値のばらつきの度合いである。
![V[X] = E[(X-E[X])^2] = E[X^2] - (E[X])^2](/mediawiki/images/math/a/8/5/a85588f23cbb363197b6e033c8d3edd4.png)
X,Yが独立のときに限り、和の分散は分散の和に等しい。
![V[X+Y] = V[X] + V[Y]](/mediawiki/images/math/4/2/3/4230cd5208e2663855b06c131d806da2.png) (ただしX,Yは独立)
(ただしX,Yは独立)
独立でない場合に生じる「ズレ」を共分散と呼ぶ。
![V[X+Y] = V[X] + V[Y] + 2Cov[X,Y]](/mediawiki/images/math/a/b/c/abc1a436af9d1ce47241d60c28236ec0.png)
共分散・相関
共分散は二組の対応する確率変数の間で、ばらつきが異なる度合いである。 共分散の定義は
![Cov[X,Y]=E[ (X-E[X]) (Y-E[Y]) ]](/mediawiki/images/math/4/9/3/4933b69a9fb47270a6166b98c8a5ac30.png)
となる。 XとYに関して対称に定義されていて、XとYのばらつきの傾向が似ていれば大きな正の値になり、似ていなければ大きな負の値になる。XとYが独立であれば0になる。 共分散をXの標準偏差とYの標準偏差で割ったものが相関係数である。
![Corr[X,Y] = Cov[X,Y] /(V[X]^{1/2}V[Y]^{1/2})](/mediawiki/images/math/5/c/d/5cdc472a0bd4515066b5be5877a20647.png)
ベイズ推定
ベイズの定理は以下のように表される。
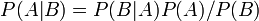
ここでP(A)を事前確率、P(A|B)を(Bが起きることを知った上でのAが起きる確率という意味の)事後確率と呼ぶ。
分布
正規分布
よく見る釣鐘型の分布。どんな分布でも、その中から要素をランダムに抽出して和をとったものの分布は、正規分布に近づく(中心極限定理)。期待値が0, 分散が1になるようにスケーリングしたものを標準正規分布といい、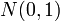 と書く。
と書く。
正規分布表
標準正規分布表の見方。
|

|
表におけるzの値は上から順に左→右方向にみる。正規分布全体の面積を1.0としたときの、 zから上側の面積を示している。例えば標準偏差が2.0以上の面積は0.0228、2.2以上の面積は0.0139。
ポアソン分布
稀にしか起こらない離散的な事象を数える際に用いる分布。 単位時間中に平均λ回発生する事象が、ぴったりk回発生する確率を
|
|

|
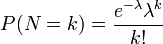
と定義する。
二項分布
コイン投げをして表裏がでる回数を記録したときにできる分布。 離散的な分布だが、フェアなコインを30回程度投げると正規分布で非常によく近似できる。
統計・推定
母集団から無作為に抽出された標本集団から、もとの母集団を統計的に推し量ることを推定という。
回帰分析
従属変数(近似したい値、目的変数ともいう)と説明変数(近似に用いるデータ)の関係を統計的に推定することを回帰分析という。 1個の説明変数から1個の従属変数を予測する場合を単回帰、説明変数を複数用いる場合を重回帰という。 従属変数をy、説明変数をxとすると
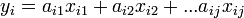
の形でパラメータa_{ij}を最小二乗法で決定する線形回帰が一般的。
点推定と区間推定
標本の値から、母集団の平均値や分散を予測することを点推定(数値を点として予測)と呼び、その推定がどれ位ずれているかを区間推定と呼ぶ。