Aritalab:Lecture/NetworkBiology/Markov Chains/Coupling
m (→カップリング) |
m |
||
| Line 75: | Line 75: | ||
同じ議論を補集合 ''S-A'' に適用すると <math>\mbox{Pr}(X_T \not\in A) \geq \pi(S-A) - \epsilon</math>。 | 同じ議論を補集合 ''S-A'' に適用すると <math>\mbox{Pr}(X_T \not\in A) \geq \pi(S-A) - \epsilon</math>。 | ||
すなわち <math> \mbox{Pr}(X_T \in A) \leq \pi(A) + \epsilon </math> であるため、時刻 ''T'' 以降に定常分布へ収束することがわかる。 | すなわち <math> \mbox{Pr}(X_T \in A) \leq \pi(A) + \epsilon </math> であるため、時刻 ''T'' 以降に定常分布へ収束することがわかる。 | ||
| + | |||
| + | ===具体例=== | ||
| + | |||
| + | ;トランプのシャッフル | ||
| + | 二組のトランプを用意し、一組目 <math>X_t</math> は52枚のカードから等確率で一枚選び、一番上におく。 | ||
| + | もう一組 <math> Y_t </math> のほうは、''X'' で選んだ値を同様に一番上におく。 | ||
| + | |||
| + | 選ばれて一度上に移動したカードの位置は、 ''X'' と ''Y'' の間で変わらない。 | ||
| + | そのため、カップリングするためには、全てのカードが少なくとも一度選ばれればよい。 | ||
| + | これに必要な回数は <math>n \log n + cn</math> である。 | ||
| + | いずれか一枚のカードがまだ選ばれない確率は | ||
| + | |||
| + | <math> | ||
| + | (1 - 1/n)^{n \log n + cn} \leq e^{-(\log n + c)} = \frac{e^{-c}}{n} | ||
| + | </math> | ||
| + | |||
| + | したがって ''n'' 毎のうちどれかが選ばれていない確率は高々 <math>e^{-c}</math>。 | ||
| + | 例えば、<math> n \log n + n \log (1/\epsilon) = n \log (n/\epsilon)</math> ステップたてば、カップリングしていない確率は高々 <math>\epsilon</math> になる。 | ||
Revision as of 10:16, 1 July 2010
分布間の距離
二つの確率分布 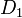 と
と 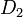 の距離を次のように定義する。
の距離を次のように定義する。
変動距離: 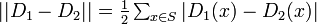
右辺の係数 1/2 は 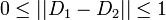 を満たすためについており、
を満たすためについており、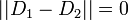 なら全要素について分布が等しいから
なら全要素について分布が等しいから 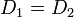 である。また距離が 1 のときは確率が正となる状態の集合が独立であることを意味している。
である。また距離が 1 のときは確率が正となる状態の集合が独立であることを意味している。
変動距離は、特定の事象に対する確率の差を用いても定義できる。
任意の 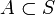 において
において 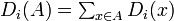 とする。このとき
とする。このとき
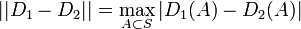
- 証明
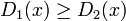 を満たす状態の集合を
を満たす状態の集合を 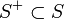 、
、
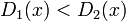 を満たす状態の集合を
を満たす状態の集合を 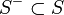 と書く。
このとき
と書く。
このとき
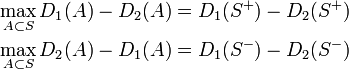
また
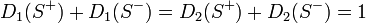
より
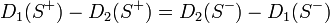
したがって
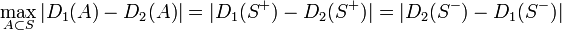
最後に
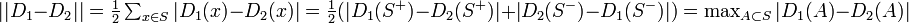 (証明おわり)
(証明おわり)
カップリング
状態空間 S 上のマルコフ連鎖 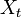 ,
, 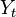 がカップリング (coupling) するとは、時刻 t 以降に二つの確率過程が同じ状態を取ること、つまり
がカップリング (coupling) するとは、時刻 t 以降に二つの確率過程が同じ状態を取ること、つまり 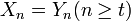 をいう。この時刻 t をカップリング時間という。
をいう。この時刻 t をカップリング時間という。
規約でエルゴード的なマルコフ連鎖は、任意の初期分布と定数  に対して、ある数 T が存在し、 T ステップ後に定常分布との間の変動距離を 以下にすることができる。
に対して、ある数 T が存在し、 T ステップ後に定常分布との間の変動距離を 以下にすることができる。
定常分布を表す 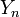 と、任意の状態集合 において
と、任意の状態集合 において
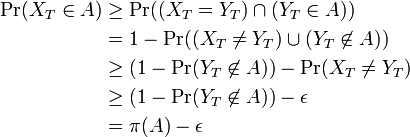
同じ議論を補集合 S-A に適用すると 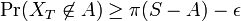 。
すなわち
。
すなわち 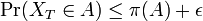 であるため、時刻 T 以降に定常分布へ収束することがわかる。
であるため、時刻 T 以降に定常分布へ収束することがわかる。
具体例
- トランプのシャッフル
二組のトランプを用意し、一組目 は52枚のカードから等確率で一枚選び、一番上におく。
もう一組 のほうは、X で選んだ値を同様に一番上におく。
選ばれて一度上に移動したカードの位置は、 X と Y の間で変わらない。
そのため、カップリングするためには、全てのカードが少なくとも一度選ばれればよい。
これに必要な回数は 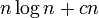 である。
いずれか一枚のカードがまだ選ばれない確率は
である。
いずれか一枚のカードがまだ選ばれない確率は
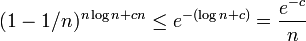
したがって n 毎のうちどれかが選ばれていない確率は高々 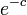 。
例えば、
。
例えば、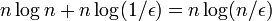 ステップたてば、カップリングしていない確率は高々 になる。
ステップたてば、カップリングしていない確率は高々 になる。